

Long live World Action Models
The latest survey on World Action Models, RLWRLD Open-Sources RLDX-1, and more industry updates from NVIDIA, HuggingFace, and Physical Intelligence
Last week we flagged Shengshu’s MotuBrain as evidence that “VLAs might be the wrong approach.” This week the World Action Model camp formalizes with a new survey and an updated taxonomy.
The Latest Survey on World Action Models
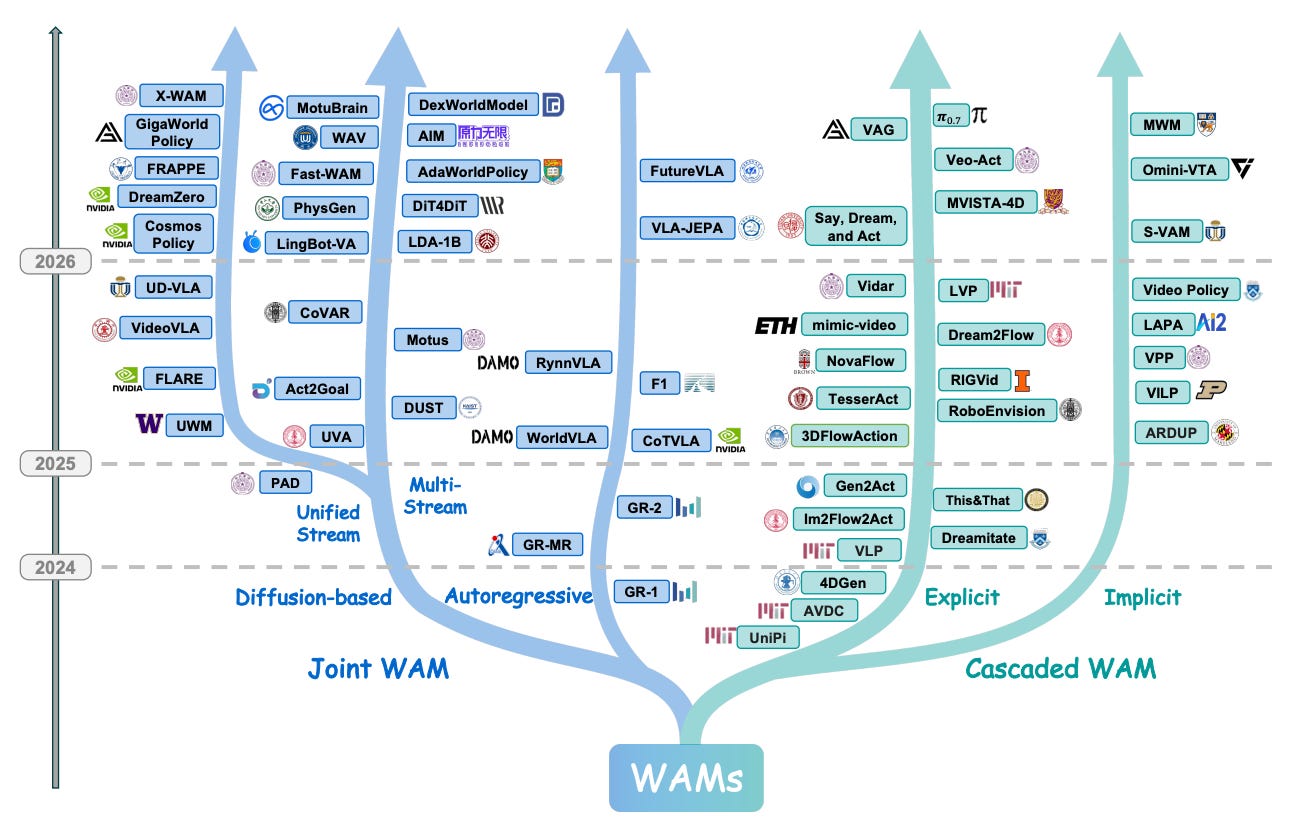
Wang et al. (Fudan / NUS) formally define a World Action Model as
“embodied foundation models that unify predictive state modeling with action generation, targeting a joint distribution over future states and actions rather than actions alone.”
In Plain English:
a VLA takes an observation and a language instruction and outputs an action.
a pure world model takes an observation and an action and predicts the next observation.
a WAM takes observation and language and outputs both the next observation and the action — one network, jointly trained.
The structural case is two-fold. First, VLAs “learn reactive observation-to-action mappings without explicitly modeling how the physical world evolves under intervention,” which the paper argues caps generalization. WAMs make future-state prediction a first-class training signal. Second, the WAM training tuple includes the next observation, which means unlabeled internet video becomes first-class training data — no action labels required. If that data argument holds at foundation scale, the data-collection economics of the entire field shift.
WAMs split into Joint (one network produces both the next observation and the action) and Cascaded (a world model stacked behind or alongside a policy). Joint further splits into Diffusion-based, Autoregressive, Multi-Stream, and Unified-Stream.
Cosmos Policy, GR-2, VLA-JEPA, Dreamcite, NovaFlow, and last week’s MotuBrain all map onto the same tree. The contribution is largely that mapping — and it explains, structurally rather than empirically, why MotuBrain’s data-efficiency gap to standard VLAs looks the way it does.
Link: arxiv.org/abs/2605.12090
Research
RLWRLD Open-Sources RLDX-1: Dexterity-First, Multi-Stream

Korean startup RLWRLD released RLDX-1, an 8.1B-parameter foundation model built on a Multi-Stream Action Transformer that fuses vision, motion, working memory, and torque streams — explicitly arguing that dexterity is gated on force and tactile signals, not bigger VLMs.
The visual tower is a fine-tuned Qwen3-VL 8B; teleoperation data is amplified ~5x via Cosmos-Predict2 synthetic video for a measured 9.2% success-rate lift. Three checkpoints are live on Hugging Face (RLDX-1-PT, RLDX-1-MT-ALLEX, RLDX-1-MT-DROID). On the WIRobotics ALLEX humanoid, RLDX-1 hits ~90% on tasks where comparable baselines sit below 30%, including 70.8% on a pot-to-cup pouring benchmark — roughly 2x prior published numbers. It sits on the Joint/Multi-Stream branch of the WAM tree but adds force as an extra stream, a design axis the survey above doesn’t dwell on. Open weights mean teams can actually evaluate it against their own pipelines.
Links: rlwrld.ai/en/rldx-1 | huggingface.co/RLWRLD/RLDX-1-PT
This Week’s arXiv: Three Inference Tricks for Production VLAs
The strongest cluster on cs.RO (arXiv’s category code for Computer Science → Robotics) this week is about making existing VLAs cheaper and faster, not bigger.
Premover turns the seconds-long gap while a user is still typing an instruction into VLA inference time — two small projection heads on top of a frozen backbone plus a learned readiness threshold cut wall-clock on LIBERO 34.0s → 29.4s with no accuracy hit (95.1% vs 95.0%); naive early-action baselines collapse to 66.4%.
Kairos schedules the execute phase, not just generate, across multi-robot fleets and reports 31.8–66.5% end-to-end latency reductions — one of the rare papers on the production-serving layer of Physical AI.
OneWM-VLA compresses each camera view to a single semantic token per frame via Adaptive Attention Pooling, trains a world module on top of frozen π₀ with 14.71M LoRA parameters, and lifts real-robot cloth-folding 20% → 60%. Read together, the gains are coming from the periphery — scheduling, token budgets, instruction-time idle — not bigger backbones.
From Pixels to Tokens: Where Latent-Action Supervision Wins
Systematic study of latent-action supervision approaches for VLAs. Image-based latent actions favor long-horizon and scene generalization; action-based supervision favors motor coordination; discrete latent action tokens fed directly into the VLM outperform both. Useful priors if you’re designing a fresh pretraining recipe.
Link: arxiv.org/abs/2605.04678
Industry
Hugging Face Opens Reachy Mini Appstore — 10,000 Units Sold
Hugging Face and Pollen Robotics opened an “agentic appstore” for the Reachy Mini desktop robot. Every app is a Hugging Face Hub repository — searchable, forkable, one-click installable from the device — with ~200 apps live at launch.
Disclosed sales: 10,000 units to date, 3,000 in the past two weeks, ~1,000 more in the next 30 days. Reachy Mini starts at $299. The unit count is the news. This is the first non-trivial fleet of identical, internet-connected robots running community-authored policies — a low-cost target to publish demos against, and (depending on what HF collects) a candidate dataset source. The “app = HF repo” pattern is also worth tracking: pip install for robot behaviors.
Link: huggingface.co/blog/clem/reachymini-appstore
JAL and GMO Start Two-Year Humanoid Trial at Haneda
JAL Group and GMO AI & Robotics began operating Unitree G1 and UBTech Walker E units at Haneda Airport for baggage handling and cabin cleaning. Two-year horizon, defined task scopes, real production environment — a useful reference point for what “deployment” actually means for humanoids in 2026. Stack uses 3D LiDAR, depth cameras, and voice input.
Link: press.jal.co.jp/en/release/202604/009502.html
Worth Watching
ICRA 2026 (Vienna, June 1–5): three weeks out. Camera-ready papers drop next week and the “From Data to Decisions: VLA Pipelines for Real Robots” workshop schedule should firm up. Directly in our space.
AGIBOT World 2026 Phase 2: Phase 1 (imitation learning, free-form teleoperation, real + 1:1 digital twin) landed in April. The open question for Phase 2 is whether the data format pairs each observation with its next observation cleanly — which would make it the first WAM-native large public dataset.
NVIDIA GR00T N2: Huang teased “end of year” at GTC. If the cadence holds, first leaks should land in this part of the calendar.
Ai2 releases MolmoAct 2: Last August, Ai2 launched MolmoAct, the first Action Reasoning Model (ARM)—a new class of models that reason about their environment in 3D before they act. MolmoAct 2 is a substantial upgrade that outperforms capable proprietary robotics models on industry benchmarks, handles various real-world tasks out of the box without per-task fine-tuning, and runs up to 37x faster than its predecessor—vastly expanding the types of work it can do.
Alongside MolmoAct 2, Ai2 released the MolmoAct 2-Bimanual YAM dataset, the largest open-source bimanual tabletop manipulation robotics dataset ever published, with over 720 hours of training demonstrations.
HumanNet - 1M hours of human video for robot training
Shows that 1,000 hours of egocentric human video matches 100 hours of real robot data for VLA training. If this holds, it changes the economics of training robot foundation models entirely.
arXiv: https://arxiv.org/abs/2605.06747World Model for Robot Learning survey (Abbeel, Malik, Du et al.)
The most-upvoted robotics paper of the period (312 HF upvotes). Definitive reference on world models for robotics from Berkeley/Stanford/CMU. The scout included a Fudan WAM survey but missed this higher-impact one.
arXiv: https://arxiv.org/abs/2605.00080
Project page: https://ntumars.github.io/wm-robot-survey/